
Context
- Data preparation for clustaring model
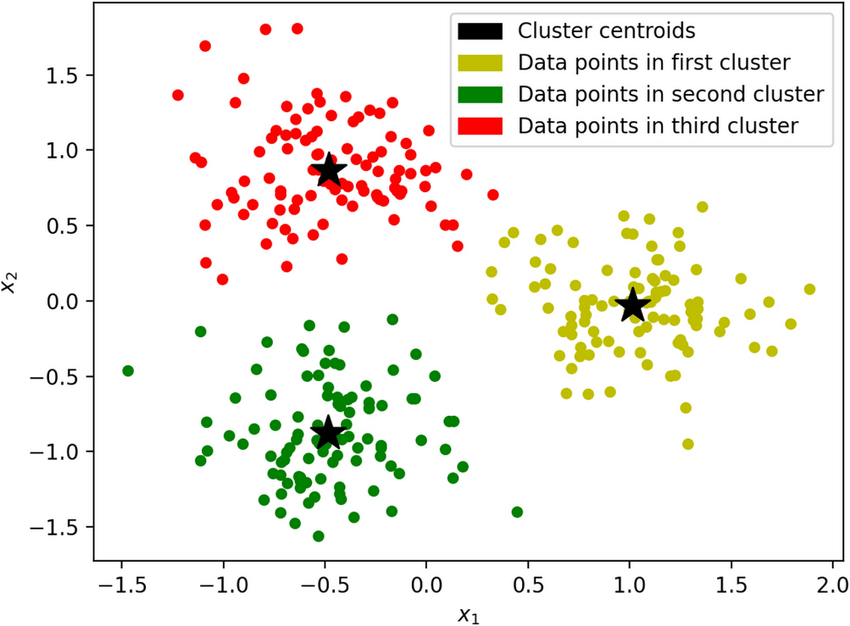
- After defining the objectives and have a better understanding of our data, we need to preprocess the data to meet the model requirement. This where scaling our data comes into play.
Normalizing Data
- You can transform data for multiple features to the same scale by normalizing the data. In particular, normalization is well-suited to processing the most common data distribution, the Gaussian distribution
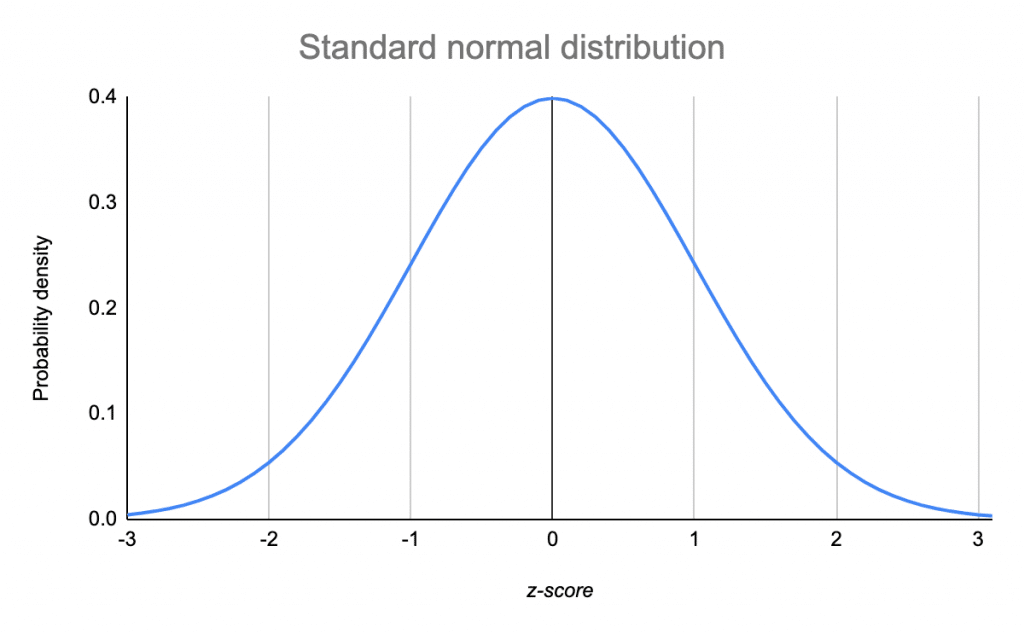
In general apply normalization when either of the following are true:
- Your data has a Gaussian distribution.
- Your data set lacks enough data to create quantiles.
Using the Log Transform
- Sometimes, a data set conforms to a power law distribution that clumps data at the low end.
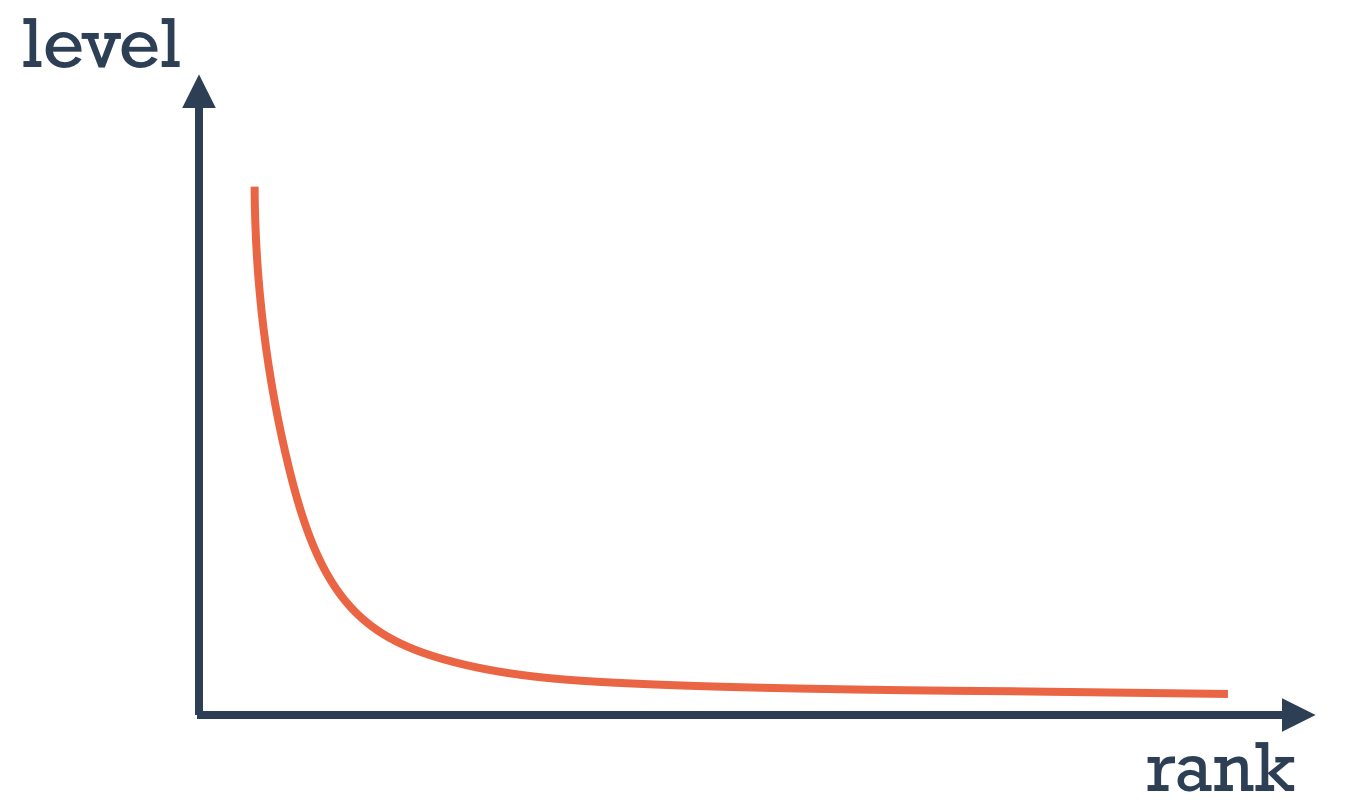
Summary:
- Applay Log for data that follows power low distribution
### Using Quantiles
Normalization and log transforms address specific data distributions. What if data doesn’t conform to a Gaussian or power-law distribution?
Convert your data into quantiles by performing the following steps:
- Decide the number of intervals.
- Define intervals such that each interval has an equal number of examples.
- Replace each example by the index of the interval it falls in.
- Bring the indexes to same range as other feature data by scaling the index values to [0,1].
Resources
- https://developers.google.com/machine-learning/clustering/prepare-data